音声認識AIモデル ZipFormer
木村 優志
Published: 6/11/2025, 5:12:00 AM

ZipFormerとNext-gen Kaldi
ZipFormer は、Next-gen Kaldi にも採用されている音声認識モデルです。開発したのは中国企業のXiaomi(シャオミ)で、オープンソースとして公開されています。
日本語で、Kaldi というと、コーヒーロースターを思い出す人が多いでしょうが、この Kaldi は音声認識システムのほうです。C++で実装されており、長らく音声認識のデファクトスタンダードツールとして利用されていました。Pythonバインディングもあります。
しかし、Kaldiは、ディープラーニングフレームワークなどを利用せず、独自のC++実装となっています。拡張するためには,Kaldi独自のrecipe と呼ばれるスクリプトを書いたり、C++実装を改造したりする必要がありました。
Next-gen Kaldiからは、ディープラーニングフレームワークに PyTorchを採用しています。まだまだ開発中のきらいがあり、バグも散見されます。ですが、非常に高速、高精度な音声認識システムを実現できます。Zipformer で学習したモデルは、CPUでも十分高速に動作します。十分な学習データをあたえれば、OpenAI の Whisper より高精度な認識が可能です。
ZipFormer のアーキテクチャとパフォーマンス
ZipFormer は ICLR 2024 で発表されたモデルです。音声認識では、Conformer という CNNと Transformer を組み合わせたモデルが主流です。ZipFormerではそれの計算を省略して計算量を削減した、ZipFormer Blockを利用します。
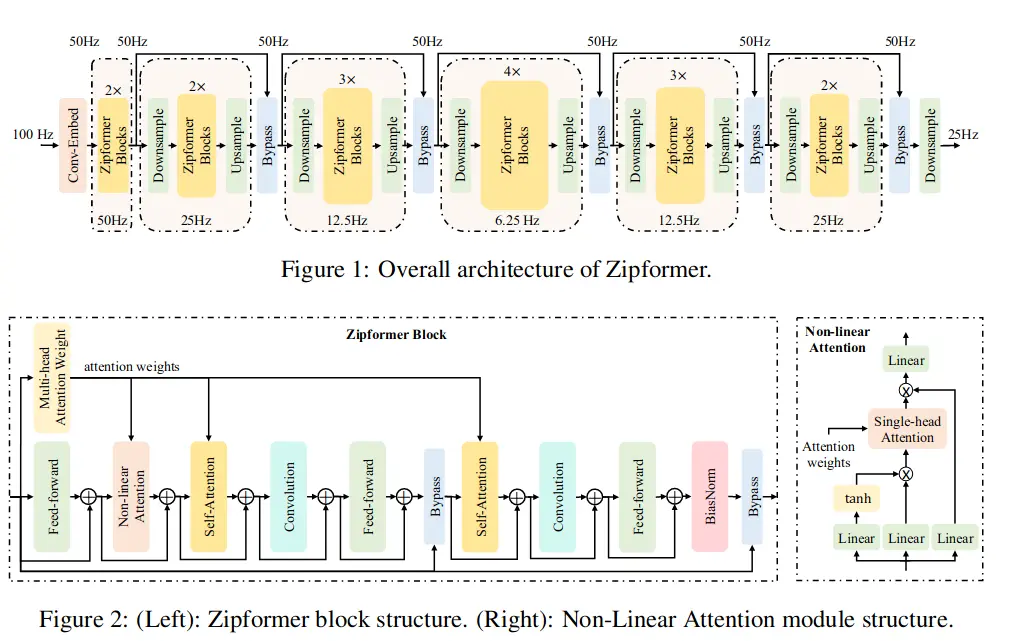
ZipFormer Block では、2種類の軽量化を図っています。図下側の Multi-head Attention Weight では、Attention Weight を1回だけ計算してをれを3回にわたって再利用しています。次に、Non-linear Attentionでは、計算量の高い 内積の代わりに計算量の少ない要素積を利用しています。また、全体では、ダウンサンプリングを活用して、計算量を削減しています。印象としては、そんなことしていいの?と言ってしまいたくなるぐらい荒っぽく計算量を削っています。
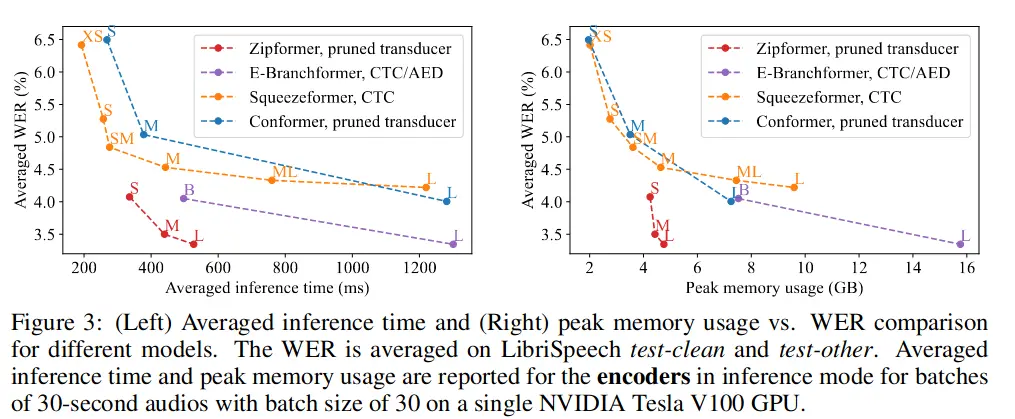
上図は他のモデルと比較したときのZipFormerのパフォーマンスです。下にあるほど精度が高く、左にあるほど、計算時間が短い(左図)、メモリ使用量が少ない(右図)ことを示しています。ZipFormer は、他のモデルと比べて、左下側に集まっており、精度が高く、軽量であることが見て取れます。
まとめ
今回は、音声認識モデルである、ZipFormerを紹介しました。今後、Next-gen Kaldiの開発も進み、安定したツールとなっていくことでしょう。